Cómo hacer recuentos de archivos e interpretarlos

Por Lorena Ramírez, Jefe de proyectos
Hoy vamos a tratar un tema al que no se le suele prestar mucha atención pero que, sin duda, es fundamental para todo traductor profesional freelance: la interpretación de recuentos de archivos realizados con herramientas TAO.
En ocasiones, cuando recibimos un encargo de servicios de traducción, ya nos viene dado el número de palabras que vamos a traducir o a revisar gracias al uso de alguna herramienta TAO, pero eso no debería bastarnos, conviene saber interpretar estos datos y comprobar que se ajustan a la realidad… Por un lado, porque podría haber un error en el recuento inicial —se gestionan muchos proyectos y alguna vez puede darse el caso— y, por otro lado, porque saber interpretar los recuentos nos ayuda a la hora de calcular el tiempo que vamos a dedicar a la tarea. ¿Nunca os ha dado la sensación de haber tardado más de lo previsto según el recuento recibido? Pues, esto os puede ayudar a prever estos casos…
En primer lugar vamos a ver cómo realizar nosotros los recuentos con algunas de las herramientas más comunes con las que trabajamos (Studio y Translation Workspace) y, a continuación, veremos cómo interpretarlos.
Hacer recuentos
Todas las herramientas TAO tienen una opción para analizar los archivos con los que se va a trabajar y extraer los recuentos.
Si trabajamos con Translation Workspace, tenemos que tener instaladas las Translation Workspace Tools, desde donde podemos hacer el análisis a través de la opción Analyze.

Una vez introducidas las credenciales, aceptamos la ventana emergente con la configuración que viene dada y, seguidamente, elegimos la memoria de traducción del proyecto y la combinación de idiomas. En la siguiente ventana, arrastramos el archivo que queramos analizar, seleccionamos la ruta donde vayamos a guardar el recuento y marcamos la opción Use Analysis TM.
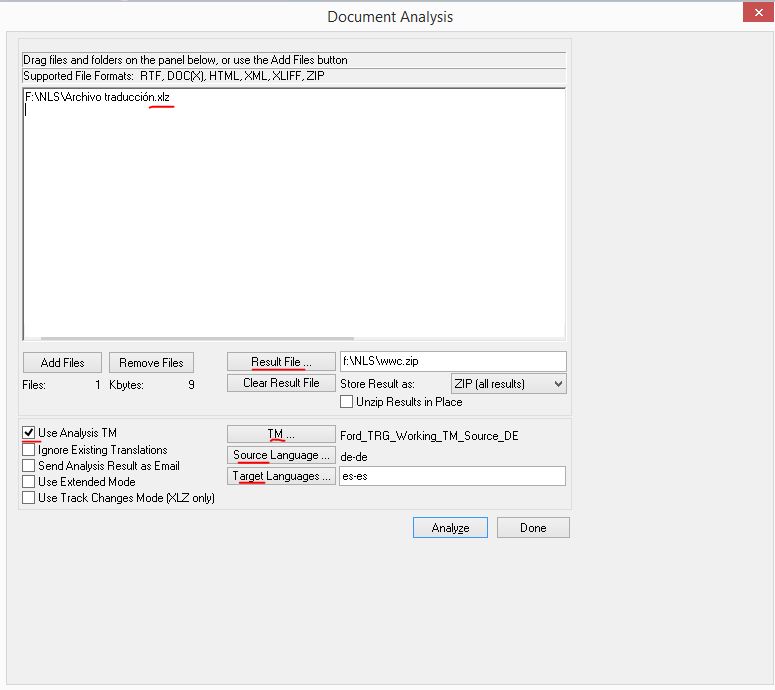
Se creará un zip con el recuento en diferentes formatos, tomamos el archivo .txt cuyo nombre acaba en _anatm.
Desde TWS XLIFF Editor también podemos hacer el recuento desde la opción Batch operations que encontramos al desplegar Translation Workspace en la barra de menú.
Si trabajamos con Studio, una vez abierto nuestro proyecto hacemos clic en el botón derecho y elegimos Tareas por lotes y, a continuación, Analizar archivos. Aceptamos cada ventana, hasta que llegamos a la configuración, donde debemos realizar los siguientes ajustes:
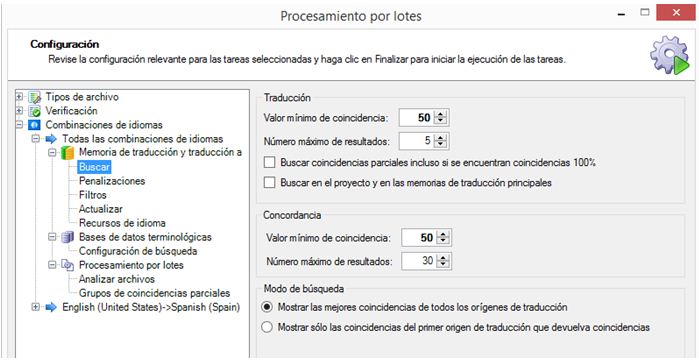
En Combinaciones de idiomas → Todas las combinaciones de idiomas:
→ Memoria de traducción (comprobamos que la TM del proyecto está seleccionada) → Buscar (configuramos el valor de coincidencia de traducción y concordancia al 50 %)
→ Procesamiento por lotes → Analizar archivos (marcamos las dos primeras casillas)
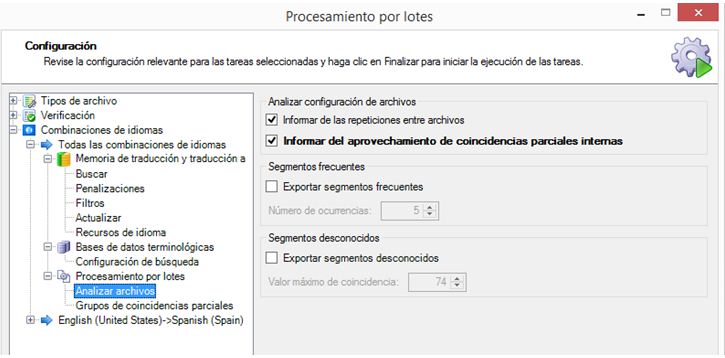
Podemos consultar el análisis en la opción Informes y guardarlo como un archivo Excel en nuestro ordenador.
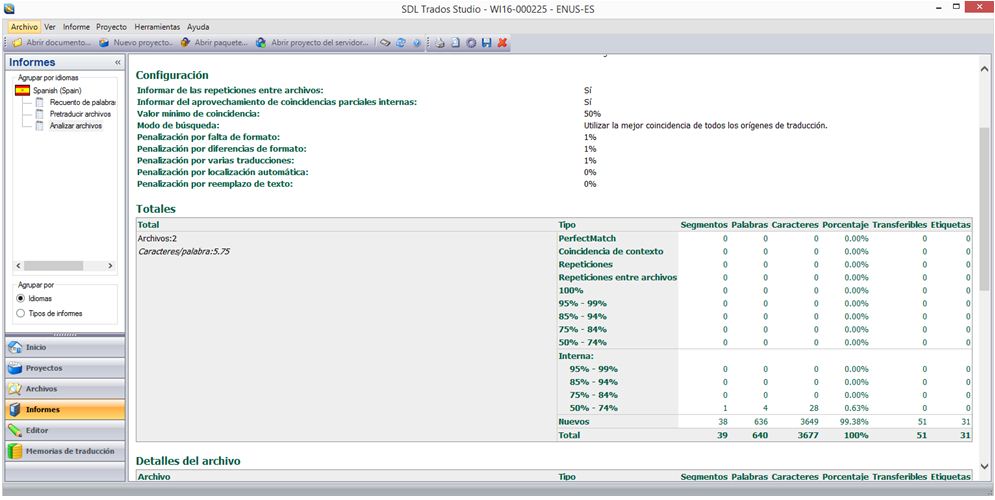
Interpretar recuentos
Una vez hechos los recuentos, lo primero que debemos hacer es comprobar que se corresponden con los recuentos que nos ha mandado el cliente. Al trabajar con memorias en línea (como en el caso de XLIFF Editor), es posible que los recuentos varíen ligeramente, pero si apreciamos una diferencia considerable respecto a los recuentos del cliente, debemos comunicárselo antes de empezar con la traducción.
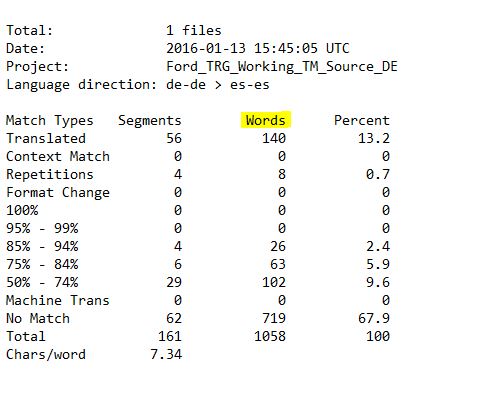
Vemos ahora dos ejemplos de recuentos obtenidos con las herramientas mencionadas:
TWS
Studio
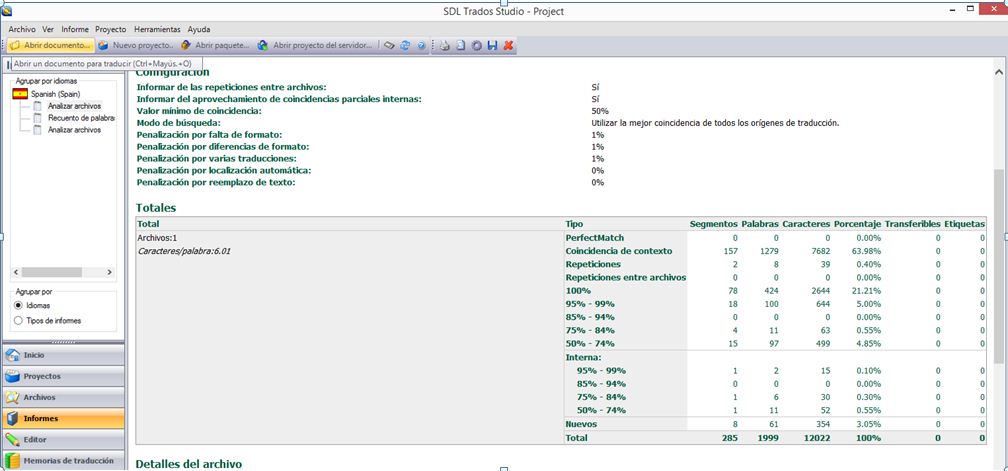
En este último caso, hemos elegido que se aprovechen las coincidencias parciales internas, por lo que debemos sumar los resultados de los porcentajes iguales para obtener el total de cada uno de ellos (p. ej., en la franja de 95 % – 99 %, el total de palabras sería 102).
En general, las palabras totales nos dan información sobre la extensión del archivo y el resto de franjas, sobre la parte que nosotros vamos a traducir.
– Repeticiones: son las palabras que se repiten dentro del texto objeto de traducción, por lo que en este caso, no vamos a necesitar dedicarle apenas tiempo, prácticamente el de abrir y cerrar el segmento.
– 100 %: son las palabras que coinciden al 100 % con palabras de la TM (exact match); se trata más bien de revisar la traducción existente, por lo que tampoco requieren mucho tiempo.
– Franjas entre 99 % y 75 %: son palabras que coinciden en esa proporción con las palabras de la TM (high fuzzy); en estos casos, la coincidencia con las palabras de la TM es alta, por lo que la traducción debe ser rápida. Lo más importante en estos casos es tener cuidado de no dar por válido un segmento con información que no corresponda con el source actual, ya que al salirnos una coincidencia alta, puede confundirnos y hacer que o bien dejemos información que no corresponde del segmento que nos propone o que omitamos algún dato adicional que aporta nuestro segmento.
– 50 % – 74 %: son las palabras que coinciden entre un 50 y un 74 % con palabras de la TM (low fuzzy); en este caso la coincidencia es baja, por lo que solo vamos a tener una pequeña ayuda a la hora de traducir el segmento.
– Nuevas (no match): son palabras que no vamos a encontrar en la TM, por lo que tenemos que traducirlas desde cero.
Es importante que tengamos en cuenta estas consideraciones a la hora de afrontar la traducción, ya que nos puede ayudar a prever la dedicación que va a requerir la tarea.
Pero esto no es todo, existen también herramientas que nos ayudan a hacer estos cálculos y a que obtengamos un recuento compensado, es decir, el número de palabras definitivas que vamos a traducir como si fueran nuevas. Para ello, se le asigna un porcentaje a cada una de las franjas anteriores que corresponde con el grado de dificultad y dedicación de cada una de ellas. Estos porcentajes de compensación pueden variar según el cliente, ya que son también los porcentajes que se utilizan a la hora de fijar el precio de las palabras (como es evidente, no se considera igual, a todos los efectos, una palabra nueva que una con una coincidencia del 95 %, por poner un ejemplo).
Una herramienta gratuita que podemos utilizar para compensar los recuentos es CATCount. Una vez abierta, pinchamos en Scheme → Load y seleccionamos el archivo con los porcentajes para cada franja que queramos utilizar. Si no tenemos ninguno, añadimos los porcentajes manualmente y, a continuación, pinchamos en Scheme → Save as… y lo guardamos como plantilla para futuros recuentos.
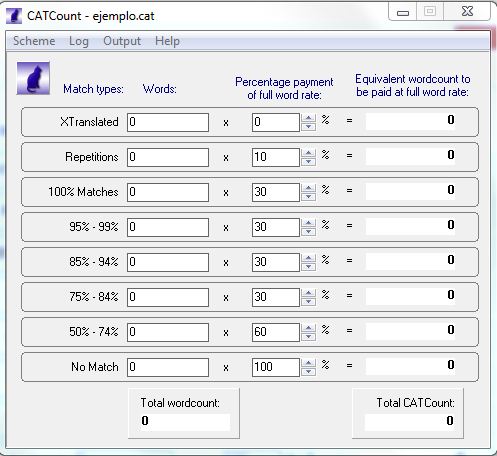
Ahora debemos rellenar cada franja con las palabras obtenidas en los análisis vistos anteriormente y obtendremos el recuento total compensado (Total CATCount) y el número total de palabras sin tener en cuenta las coincidencias con la TM (Total wordcount).
Veamos el ejemplo con el recuento que obtuvimos con TWS:
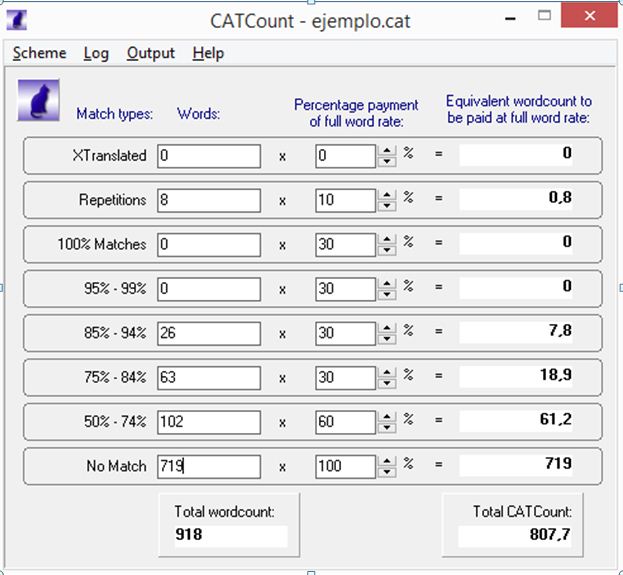
En este caso, observamos que hay que traducir un total de 918 palabras, pero que compensadas se quedan en 807, por lo que tendremos que calcular nuestro tiempo en función de esta cifra. Así, si nuestra media es de unas 350 palabras/hora, lo normal es que dediquemos aproximadamente 2,3 horas (2 horas y 20 minutos) en traducir el archivo.
Espero que os haya gustado y os animo a que incluyáis esta tarea a vuestro proceso de trabajo para que os ayude a planificaros y a reducir en lo posible los imprevistos.
¡Hasta pronto!





3 respuestas a "Cómo hacer recuentos de archivos e interpretarlos"
María dice:
22 marzo 2016
Gracias por compartir!
Me estreno como traductora en diferentes proyectos con distintas agencias de traducción y me viene genial conocer todas estas herramientas…
Esperando ya la siguiente entrada!
Saludos
Lorena dice:
29 marzo 2016
Hola, María:
Muchas gracias por tu comentario. Me alegro mucho de que te haya servido.
Mucha suerte en tu estreno como traductora y… ¡Hasta la próxima! 🙂
Lorena R.
Siân dice:
19 noviembre 2018
Llego 2,5 años tarde, pero la recomendación de la herramienta CATCount me parece muy útil.
¡Gracias!