



Daniel Ángel, Jefe de proyectos – Sénior
¡Hola a todos! Siguiendo la tónica del primer capítulo de este post que publiqué en marzo de este año, en este segundo artículo sobre el uso de Wordfast Pro seguiré hablando sobre algunas opciones de la herramienta y en qué manera ayudan o afectan al trabajo de jefe de proyectos en una empresa de traducción. Hoy me centraré en otras dos funciones fundamentales tanto antes de empezar a trabajar en un archivo como para finalizar todo el proceso de traducción y revisión. Sin más dilación, empecemos:
Analyze
Esta pestaña de la perspectiva del PM en Wordfast Pro nos servirá para realizar recuentos de archivos TXML tanto con una memoria en línea como con una memoria local. A la hora de seleccionar las opciones adecuadas para realizar el recuento hay que tener en cuenta de qué modo queremos que se visualicen, o no, los distintos tramos de fuzzy matches. Una vez arrastramos el o los archivos txml al cuadro, debemos seleccionar la memoria que vamos a utilizar para el recuento y, a continuación, una de estas tres configuraciones:
- Recuento sin calcular fuzzy matches internas


De este modo el sistema no solo no reconoce las repeticiones internas, sino que tampoco las coincidencias internas. Este recuento es realmente sencillo pero no representa el recuento real, pues lo habitual es que entre los archivos de un mismo proyecto se pueda aprovechar algo de recuento con coincidencias parciales. Como ejemplo hemos hecho una prueba con dos archivos y una memoria local y este ha sido el resultado:
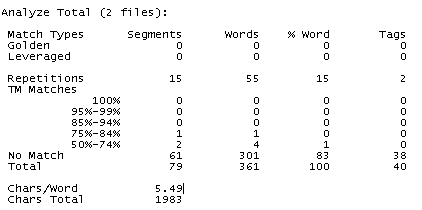

- Recuento calculando las fuzzy matches internas aparte


En este caso debemos especificar siempre el tramo mínimo a partir del cual queremos que la herramienta considere las coincidencias parciales como tales en lugar de texto nuevo. Como no hemos marcado la casilla Include Internal Fuzzy matches as TM Matches, las coincidencias parciales internas se reflejan aparte en la parte superior del recuento. Si os fijáis en el nuevo recuento, las coincidencias parciales (no internas) siguen siendo las mismas que las del recuento anterior, pero el tramo de palabras nuevas se ha visto reducido gracias a las coincidencias parciales internas que se han reconocido.
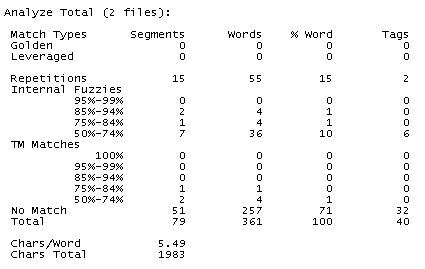

- Recuento incluyendo las coincidencias parciales internas en las estadísticas de la TM


Al marcar la opción descrita anteriormente, los mismos tramos de fuzzy matches internas que se contabilizaron en el ejemplo anterior se han incluido dentro de las coincidencias de la TM, sumándose a los tramos de fuzzy matches originales. El resultado es el recuento que solemos encontrar en la mayoría de las herramientas, si bien es cierto que SDL Trados Studio también separa las fuzzy matches internas de las coincidencias de la TM en su recuento.


Otra opción de la que debemos hablar es el formato con el que se generan los recuentos. Hay dos formatos disponibles: archivo CSV en formato tabulado para exportarse a Excel, o bien directamente un cuadro en la pantalla con el recuento (como en los ejemplos anteriores).


Si seleccionamos el formato CSV, necesitamos importar el archivo en Excel para verlo convenientemente. De hecho, si abrís el archivo CSV encontraréis un bonito jeroglífico.


Mediante el menú Datos, importamos el archivo CSV y señalamos la delimitación de las celdas tal y como se muestra a continuación.
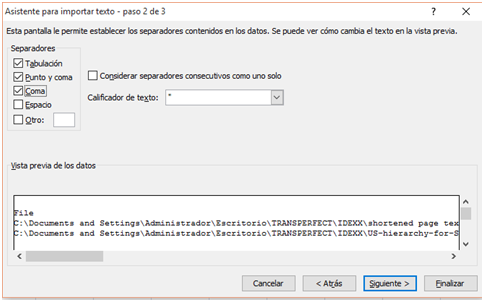

Una vez hecho esto, solo tenemos que editar el archivo resultante para que los encabezados de los tramos coincidan con las columnas de palabras (Words) en lugar de con las de segmentos.
![]()

El comentario Grinch
El único aspecto negativo que puedo resaltar de esta función es que si queremos hacer un recuento de varios archivos con una TM en línea, el proceso puede ser realmente lento, puesto que el sistema va verificando segmento por segmento para realizar los recuentos. De modo que si tenemos varios archivos que suman miles de segmentos, id a pasear al perro, haced la compra y sacad la ropa de temporada… puede que igual entonces ya haya terminado.
Transcheck
Una vez que tenemos en nuestro poder los archivos traducidos y revisados, nunca está de más realizar algunas comprobaciones para asegurarnos de que se han cumplido todas las directrices del proyecto. Para ello la opción Transcheck de la perspectiva del TM nos resulta de gran ayuda.
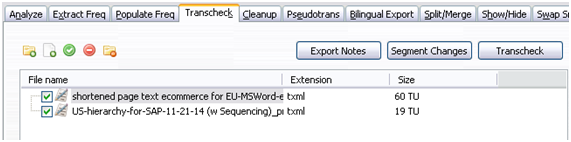

Gracias a ella, con solo arrastrar los archivos pertinentes, podemos seleccionar entre una gran variedad de comprobaciones automáticas similares a las que encontramos en otras herramientas de comprobación de la calidad como la Linguistic Toolbox de Translation Workspace o Xbench de Apsic.


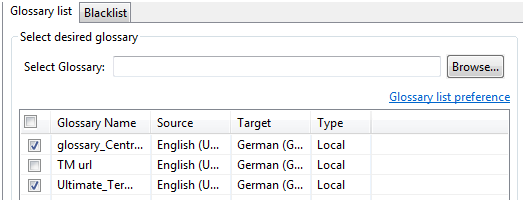
Asimismo, si tenemos que trabajar con glosario, es posible añadirlo a las comprobaciones para que el informe final incluya las posibles incoherencias que se puedan dar con respecto al glosario en línea o local proporcionado por el cliente.

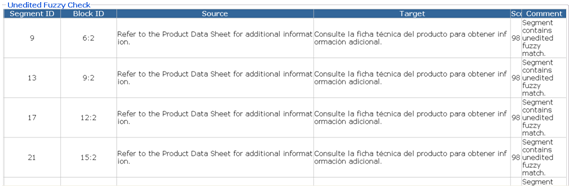
El resultado es un archivo HTML con entradas relativas a los errores detectados divididos por archivo y tipo de error. Tal como ocurre con la mayoría de las herramientas de comprobación de calidad, no todo lo que se incluye en el informe tiene por qué ser un error, casi siempre la mayoría de las entradas son realmente falsos positivos, pero nos sirve de guía para resolver esas pequeñas incidencias de las que a veces no nos damos cuenta y pueden dar al traste con la correcta finalización de un proyecto.

El comentario Grinch
¿Qué echo de menos en una función como esta? Pues es bien sencillo: un buen corrector ortográfico. Sin esto da la impresión de que el resto de comprobaciones pueden quedar relegadas a un segundo plano, o dicho de otra manera: el texto traducido podría estar en cantonés que igualmente esta opción de comprobación de calidad ni se daría cuenta. Si bien el editor de Wordfast Pro cuenta con un corrector ortográfico, este deja mucho que desear en comparación con el de Microsoft Word. De modo que lo más aconsejable es exportar el archivo a doc para esta última comprobación.
Espero que todas estas explicaciones os hayan servido de acercamiento a esta herramienta tan particular. ¡Hasta el siguiente post!