



Daniel Ángel, Senior Project Manager
Hi everyone! Continuing with the theme of the first chapter of this post that I published in March this year, in this second article on using Wordfast Pro I will continue to talk about some of the tool’s options and how they help or affect the work of a project manager in a translation company. Today I will be focusing on two other key functions, one for before you start working on a file and the other to complete the entire translation and review process. Without further ado, let’s start:
Analyze
This tab from the PM perspective in Wordfast Pro allows you to perform counts with TXML files, either with an online memory or a local memory. When selecting the appropriate options to perform the count, you have to consider how you want the different fuzzy matches to be displayed. When you have dragged the txml file(s) to the box, you have to select the translation memory that you are going to use for the count, and then one of the following three settings:
- Count without calculating internal fuzzy matches


This way, not only does the system ignore internal repetitions, it also ignores internal matches. This is a very simple count, but it does not represent the true count, because you can normally take advantage of fuzzy matches between files from the same project. By way of an example, we tested two files and a local memory and this was the result:
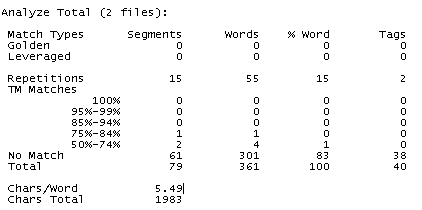

-
- Count calculating the internal fuzzy matches separately


In this case we should always specify the minimum percentage range above which we want the tool to consider fuzzy matches as such, as opposed to new text. As we have not ticked the Include Internal Fuzzy matches as TM Matches box, the internal fuzzy matches appear separately, at the top of the count. If you look at the new count, the fuzzy matches (not internal) are still the same as in the previous count, but the number of new words has been reduced due to the internal fuzzy matches that have been recognised.
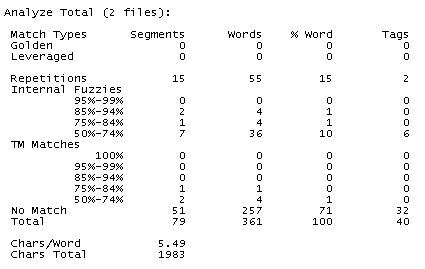

-
- Count including internal fuzzy matches in the TM’s statistics


By selecting the above option, the same internal fuzzy matches that were counted in the previous example have been included in the TM matches and added to the original fuzzy matches. The result is the count that you normally get from most tools, although it is true that SDL Trados Studio also separates internal fuzzy matches from the TM matches in its count.


Another option we should consider is the format in which the counts are generated. There are two available formats: a CSV file in tabular format to be exported to Excel, or a table displayed directly on the screen with the count (as in the above examples).


If you select the CSV format, you need to import the file into Excel to see it properly. Indeed, if you simply open the CSV you will find some pretty hieroglyphics.


Using the Data menu, import the CSV file and specify the delimitation of the cells, as shown below.
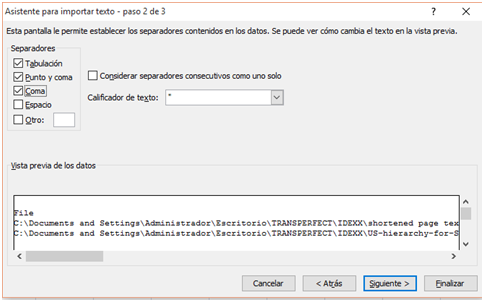

When you have done this, all that remains is to edit the resulting file so that the percentage headers match the words columns rather than the segments columns.
![]()

The Grinch says:
The only negative aspect of this function that I can highlight is that, if you want to count several files with an online TM, the process can be really slow, because the system checks them segment by segment to perform the counts. So if you have several files with thousands of segments, go and take the dog for a walk, do your shopping and pack for your holidays…maybe it will have finished when you’ve done all of that.
Transcheck
Once you have the translated and revised texts, there’s no harm in performing a few checks to make sure that all of the project guidelines have been followed. For this, the Transcheck option from the TM perspective is a big help.
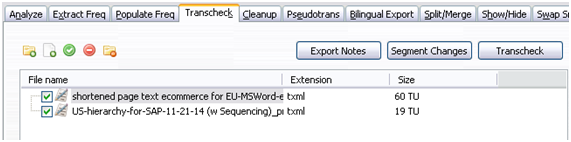

Thanks to this, all you have to do is drag the relevant files to be able to select from a wide range of checks similar to those found in other quality control tools such as Translation Workspace’s Linguistic Toolbox or Apsic’s Xbench.


Furthermore, if you have to work with a glossary, you can add this to the checks, so that the final report includes any inconsistencies that may occur with the online or local glossary provided by the client.

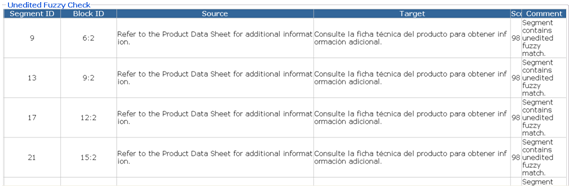
The result is an HTML file with entries for the errors detected, divided into files or error types. As with most quality control tools, not everything included in the report is necessarily an error, the majority of the entries are actually almost always false positives, but they serve as a guide to fix those minor problems that you don’t always notice and which can hinder the successful completion of a project.

The Grinch says:
What else could I possibly want from a function like this? Well it’s very simple: a good spell checker. Without this, it seems like all of the other checks amount to very little or, put another way: the translated text could well be in Cantonese and this quality control feature wouldn’t even realise. Although the Wordfast Pro editor has a spell checker, it leaves a lot to be desired compared with the one in Microsoft Word. So it’s advisable to export the file to .doc to run this final check.
I hope that all of these explanations have served as an introduction to this very special tool. Until the next post!